
In almost every major sector of the modern economy, AI-based applications are steadily revolutionizing the ways we work and our understanding of what's possible. Machine learning (ML) inferencing—the process that enables systems to draw conclusions from new data—is a key component of the AI revolution. It fuels cutting-edge technologies such as image recognition that are transforming health care, security, transportation, retail, and even agriculture. Such capabilities can offer tremendous value to businesses of all sizes, but because inferencing and other ML workloads are computationally demanding, decision makers may think that they can’t leverage AI without costly cloud solutions or expensive on-site servers with GPUs. In fact, many organizations can power their inferencing applications on site with HPE ProLiant DL380 Gen11 servers featuring 4th Gen Intel Xeon Gold processors, which include Intel AMX accelerators for improved AI performance.
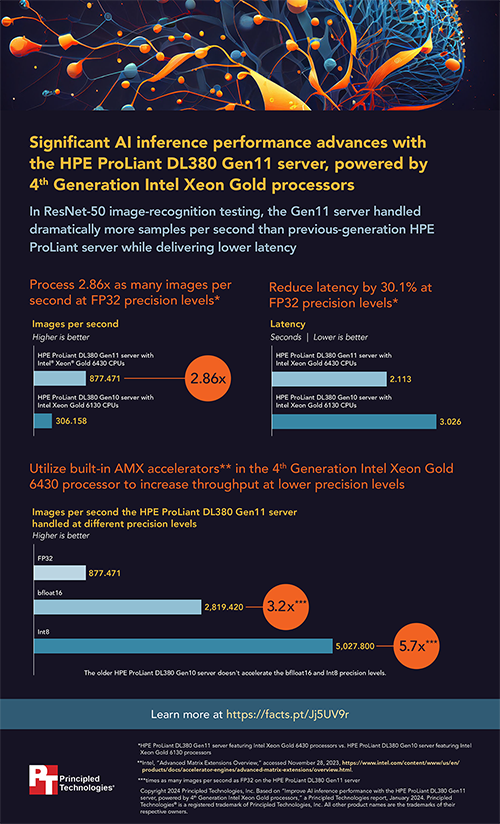
We conducted a series of image classification tests to measure the AI inferencing performance potential of an HPE ProLiant DL380 Gen11 server featuring 4th Gen Intel Xeon Gold processors. When we compared this server to its previous generation DL380 counterpart on ResNet-50 tests using FP32 precision, we found that it delivered 2.86 times the inferencing performance of its predecessor while reducing latency by 30.1 percent.
We also tested the DL380 Gen11 server at lower Int8 and bfloat16 precision levels and found its performance to be strong in both cases. Compared to the potentially high cost of consumption-based cloud services and high-end GPU-based server solutions, an HPE ProLiant DL380 Gen11 server with Intel Xeon Gold processors like the one we tested may be a compelling choice for enterprises looking for ways to leverage the power of AI inferencing applications.
To see more about our HP ProLiant DL380 Gen11 AI inference performance tests, check out the report and infographic below.



Principled Technologies is more than a name: Those two words power all we do. Our principles are our north star, determining the way we work with you, treat our staff, and run our business. And in every area, technologies drive our business, inspire us to innovate, and remind us that new approaches are always possible.



